UnSE: Unsupervised Speech Enhancement using Optimal Transport Online Supplement
Authors
Wenbin Jiang, Fei Wen, Yifan Zhang, Kai Yu
Abstract
Most deep learning-based speech enhancement methods usually use supervised learning, which requires massive noisy-to-clean training pairs. However, the synthesized training data can only partially cover some realistic environments, and it is generally difficult or almost impossible to collect pairs of noisy and ground-truth clean speech in some scenarios. To address this problem, we propose an unsupervised speech enhancement method that does not require any paired noisy-to-clean training data. Specifically, based on the optimal transport criterion, the speech enhancement model is trained in an unsupervised manner only using a noisy speech based fidelity loss and a distribution divergence loss, by which the divergence between the output and (unpaired) clean speech is minimized. Experimental results show that the proposed unsupervised method can achieve competitive performance with supervised methods on the VCTK + DEMAND benchmark and better performance on the CHiME4 benchmark.
Datasets
Setups
Compared methods
Audio Samples
| Model\id(noise) | p257_006(cafe) | p257_073(living) | p257_286(bus) | p232_227(office) | p232_378(psquare) |
|---|---|---|---|---|---|
| Clean | |||||
| Noisy | |||||
| OMLSA | |||||
| SEGAN | |||||
| SASEGAN | |||||
| DOTN | |||||
| Proposed |
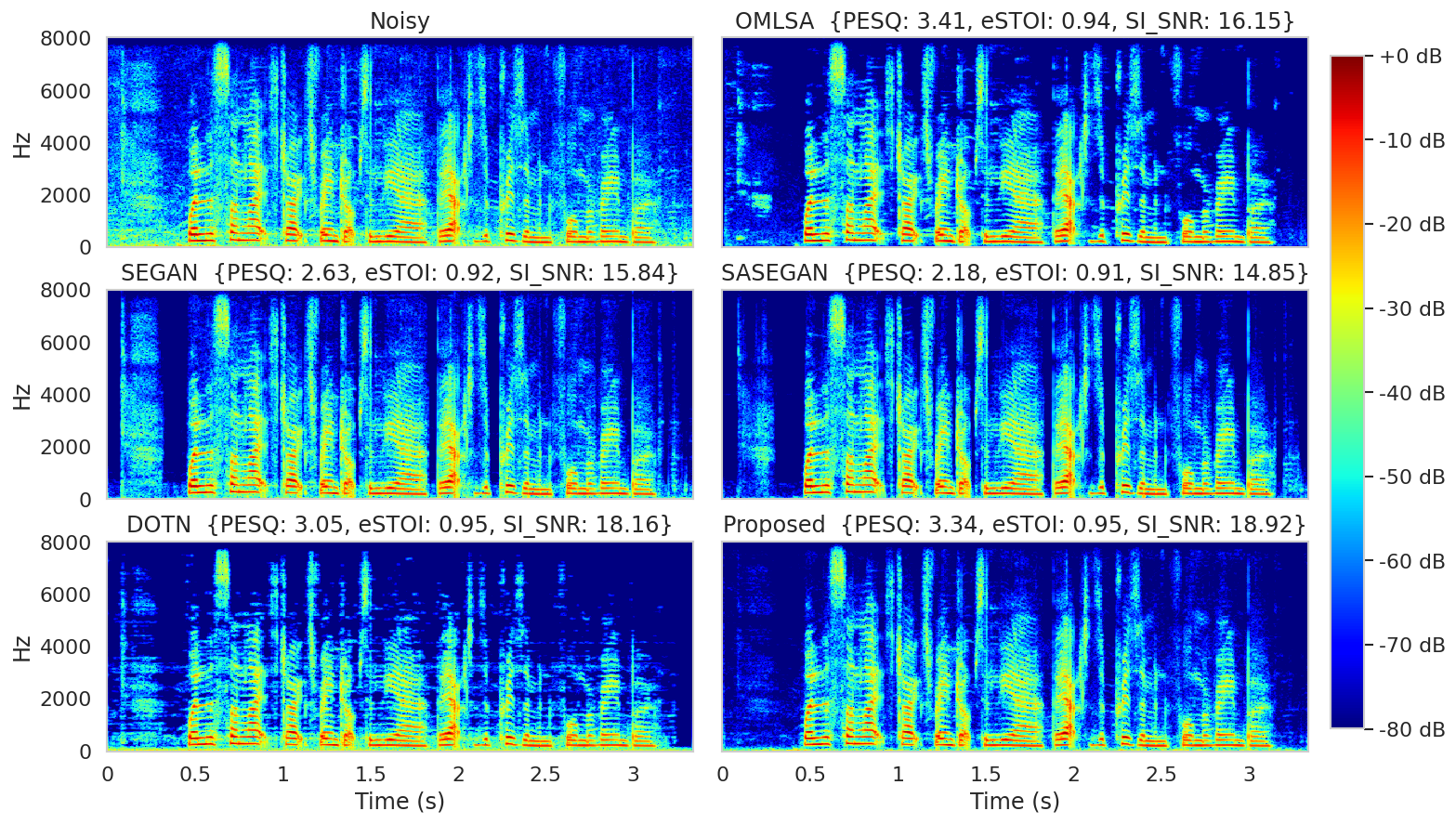
Spectrogram of the samples in first column (except clean)